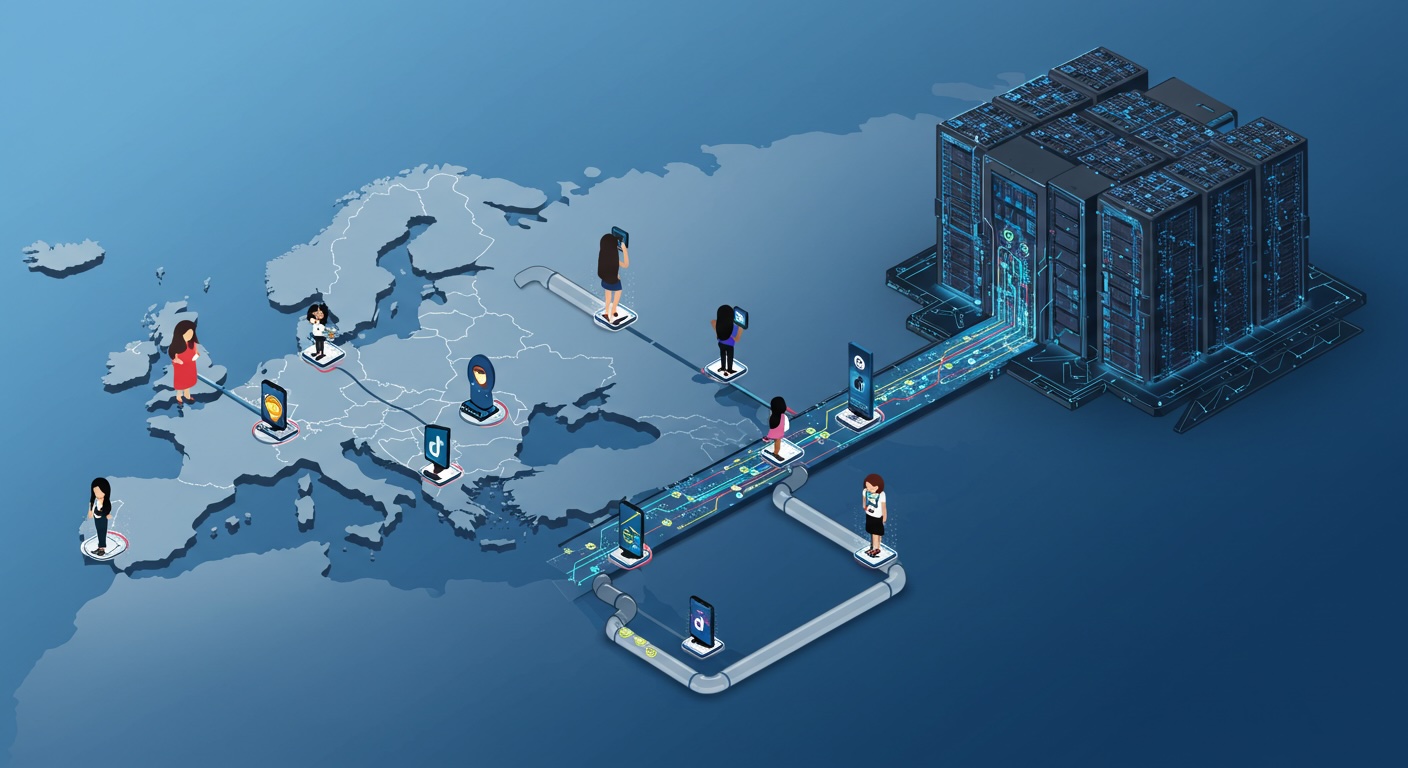
El abogado y activista austríaco Max Schrems, que ha obtenido importantes victorias judiciales para la privacidad de los ciudadanos europeos frente a compañías norteamericanas como Meta y otras explotando al límite las posibilidades del marco legal europeo, pone ahora sus ojos y los de su organización, European Center for Digital Rights (NOYB), en las aplicaciones chinas dedicadas a las redes sociales y al comercio electrónico como TikTok, WeChat, AliExpress, Shein, Temu o el fabricante de electrónica de consumo Xiaomi.
Hablamos de apps cada vez más populares en los países europeos y en todo el mundo, pero que exportan los datos personales de sus usuarios a su país de origen, en donde no pueden ser protegidos de manera realista por ser considerado China como un estado de vigilancia autoritario en el que su gobierno tiene siempre la puerta abierta para reclamar datos de sus empresas. De hecho, de las citadas compañías, cuatro de ellas admiten abiertamente que envían datos personales de ciudadanos europeos a China, mientras que las otras dos afirman que transfieren datos «a terceros países» no revelados, que parece razonable suponer que incluyan a China.
La legislación de la Unión Europea en ese sentido es clara: las transferencias de datos fuera de la Unión Europea solo están permitidas si el país de destino no socava la protección de los datos, algo imposible de garantizar en el caso de China. En ese caso, las compañías suelen recurrir a las llamadas Standard Contractual Clauses (SCC), contratos en los que el destinatario chino se compromete a respetar las protecciones de la Unión Europea aunque los datos sean procesados en suelo chino.
Para que esto sea posible, las empresas deben realizar una evaluación de impacto para verificar que los datos de los europeos están seguros en el país de destino y que las SCC no entran en conflicto con las leyes nacionales que exigen el acceso a los datos. Pero dado que China es considerado un Estado de vigilancia autoritario, se considera que ninguna empresa puede ofrecer una garantía de ese tipo, porque las leyes de protección de datos chinas, aunque estrictas en general, lo son en todo menos en el establecimiento de limitaciones del acceso de las autoridades: el gobierno siempre puede llamar a la puerta de la compañía y pedir lo que quiera.
Pero además del alto riesgo de acceso a los datos por parte de las autoridades chinas, que podrían utilizar para, por ejemplo, construir bases de datos de periodistas y otras potenciales fuentes de influencia en la opinión en otros países, está el hecho de que es prácticamente imposible para un usuario europeo o extranjero en general tratar de ejercer sus derechos bajo la ley de protección de datos china, dado que el país no cuenta con una autoridad de protección de datos dedicada e independiente, ni con ningún otro tribunal al que se puedan plantear cuestiones relacionadas con la vigilancia gubernamental.
Este es exactamente el mismo tipo de problema que surgió cuando las revelaciones de Edward Snowden en 2013 demostraron fehacientemente que ninguna compañía norteamericana estaba a salvo de que su gobierno accediese a los datos de sus usuarios, y que desencadenaron la suspensión de los acuerdos de safe harbor entre la Unión Europea y los Estados Unidos en varias ocasiones.
¿Cómo afecta esto a las relaciones bilaterales? De entrada, sitúa a las compañías chinas, que por facturación y participación de mercado ya pueden entrar en la lista de compañías especialmente vigiladas, en la situación de recibir importantes multas. Pero además, lanza un mensaje a China para que trate de adecuar su legislación de privacidad a las demandas de otros países, algo muy complejo en un país que muchos consideran como un estado de vigilancia.
Afecta también al tema más comentado en las últimas semanas, Deepseek: dado que la compañía ofrece un producto de acceso gratuito a los usuarios y un acceso corporativo a un precio muy ventajoso, es importante tener en cuenta que, dado que está radicada en China, los datos que se le suministren pasarían a ser exportados a ese país como de hecho establece su política de privacidad, lo que llevaría a plantearse a las muchas compañías que estamos utilizando Deepseek con muy buenos resultados a montar servidores propios que corran el modelo en la Unión Europea para evitar esa exportación de datos potencialmente peligrosa – algo que algunos ya hemos hecho, no solo por razones legales, sino también de coste. Perplexity incluso ha ido un paso más allá: ha instalado Deepseek, ha eliminado las restricciones del gobierno chino, y la ofrece en abierto.
Si China quiere presentarse como una alternativa a unos Estados Unidos cada vez más convertidos en un gobierno hostil e incómodo, va a tener que plantearse solucionar este tipo de cuestiones. Y una vez más, con sus denuncias planteadas en el momento adecuado, Max Schrems podría haber dado en el clavo.
This article is also available in English on my Medium page, «China’s chance to become a global AI player will depend on its data privacy laws«

Una pregunta que nos hacíamos en la oficina esta mañana.
Si nos bajamos el modelo para utilizarlo en local, ¿se le puede ir añadiendo información, por ejemplo, sobre Tiananmén?
O, ¿podría alguien en la UE montar un servicio público con este modelo e ir añadiendo información?
Ignoro qué limitaciones ofrece el modelo o su licencia de uso.
¿Será el NVDIA Project Digits la máquina ideal para ejecutar este modelo en local?
https://nvidianews.nvidia.com/news/nvidia-puts-grace-blackwell-on-every-desk-and-at-every-ai-developers-fingertips
Si, puedes ponerle documentos privados y hacerles preguntas sobre Tianamen o sobre la ropa interior de Trump… (lo puede montar tan sencillo como baja la suite AnythingLLM y ponerle documentos de contexto)
Yo la tengo con un PC normalito.
Pero si vas a redactar en castellano, catalan, vasco… es mejor usar Salamandra 7B (en local) (*)
Otra cosa, es que preguntar esas cosas sea un gilipollez. La potencia de DeepSeek R1 es el razonamiento matemático.
Te cojes el Demidovich, y pruebas como resuelve los problemas…
(*) Modelos mayores en local no los puedo usar…
Perfectamente, y de hecho, Perplexity ya lo ha hecho: ha levantado un servidor con Deepseek y le ha quitado las protecciones para que puedas preguntar lo que te dé la gana, sea sobre Tiananmen, sobre los uygures o sobre lo que quieras. La noticia es de The Information, que tiene muro de pago…
Gracias por la info
Claro, si es muy fácil usan la misma API que OpenAI. Lo han puesto en bandeja los chinos, para que se use. Si lo del Nasdaq de ayer es que tiene toda la lógica del mundo. !!
En mi humilde opinión, lo mejor es tener a nuestra disposición un modelo razonador, para repetir frases de una DB cuaqluier lorito vale, abajo he puesto un ejemplo que probé antes del Demidovich (hay un chico mexicano que prueba mates contra O1) y jhe cogido una de sus pruebas y la he repetido con R1. El resultado es igual de bueno.
Ahí es donde hace daño el R1, quien va a pagar por mates si lo tienes gratis?
Enrique
Este post sobre Meta es terrorífico
Empezó con deepseek v3, que dejó a la Llama 4 ya por detrás en los benchmarks. Para colmo de males, la «desconocida empresa china con 5,5 millones de presupuesto para formación»…
Los ingenieros se están moviendo frenéticamente para diseccionar deepsek y copiar todo lo que podamos de él. Ni siquiera estoy exagerando.
La dirección está preocupada por justificar el coste masivo de gen ai org. Cómo se enfrentarían a la dirección cuando cada uno de los «líderes» de gen ai org está ganando más de lo que costó entrenar deepseek v3 por completo, y tenemos docenas de tales «líderes»
Deepseek r1 hizo las cosas aún más aterradoras. No puedo revelar información confidencial, pero pronto será pública de todos modos.
Debería haber sido una pequeña organización centrada en la ingeniería, pero como un montón de gente quería unirse a la captura de impacto y artificialmente inflar la contratación en la org, todo el mundo pierde
https://www.teamblind.com/post/Meta-genai-org-in-panic-mode-KccnF41n
USA copia a China…
Gracias por las respuestas.
De Nada.
Ayer probé perplexity (gratis) y pude comprobar lo que anunciaba Enrique. Hay una opción «con esteroides» usando Deepseek R1. Le preguntas sobre Tiananmen y ressume los hechos. Hay un corolario, si está infuido de alguna forma en sus respuestas, tampoco es el modelo original, por lo que también hay que tener cuidado que son respuestas tomadas por el condicionante que le han metido.
Por otro lado le puse en local (con AnythingLLM) y un texto sacado de la BBC sobre Tiananmen. Y con ese contexto, también resume los hechos de 1989. Es decir, es muy fácil que las respuestas sean condicionadas
Como norma general, cuando leamos que Deepseek R1 ha dicho tal cosa debermos tener en cuenta que para estar 100% seguros que son sus respuestas que:
1) Accedemos a un servidor de ellos chino, no a otro.
2) El modelo local descargado no ha sido «tuneado» por otra fuente…
Esta derivada no la había pensado, pero gracias a darle vuelta a tu pregunta me he dado cuenta que también eso puede pasar. Es decir que las respuestas se cambien a propósito con fines que desconocemos, pero que podemos imaginar.
No, no lo han «tuneado», lo han «destuneado». Te cuento, auqnue estás harto de saberlo: los sesgos en un modelo vienen invariablemente de dos fuentes, o de los datos de entrenamiento, o de reglas añadidas (hardcoded) a posteriori. Si Deepseek hubiese sido entrenado con materiales predominantemente chinos, sería perfectamente posible que no respondiese nada o casi nada a preguntas comprometidas como Tiananmen o los uygures, porque de esos temas, simplemente, no se habla en la internet china o en sus medios, por razones evidentes. Pero como sabemos perfectamente que Deepseek ha partido para su entrenamiento de las mismas fuentes que OpenAI (y que la gran mayoría de LLMs), hasta el punto de que en ocasiones, el modelo se identifica erróneamente como ChatGPT, lo que ha ocurrido es, simplemente, que Deepseek, forzada por su gobierno, ha introducido esas reglas a posteriori, tras el entrenamiento, Al ser un modelo de código abierto, eliminarlas es trivial, y eso es, básicamente, lo que ha hecho Perplexity, «destunearlo», no «tunearlo».
Buen punto !!!
Si es así, como dicen es muy bueno saberlo.
Pero…. si hubieran querido hacerlo, ni nos damos cuenta… (1)
¿Tenemos acceso al modelo que están usando en perplexity y bajartelo?
¿O nos fiamos de lo que nos cuentan?
En cualquier caso, la pena, es que yo no sé comprobarlo, pero lo bueno es que si lo pusieran en la comunidad, alguno podría comprobarlo.
Lo que es un hecho, es que cualquiera (que sepa) puede «tunear» un modelo, y si solo te da acceso en la nube, estaremos confiando en la palabra de quien lo hace..
Desde un punto de vista más «occidental» lo bueno de tenerlo en perpelxity, es que tus datos de su uso no van directamente a los serividores chinos. Eso significa que no debe haber paranoia en su uso por parte de americanos… Lo cual es aún peor para OpenAI porque tienes un modelo razonador excelente para mates también regalado.
Nota (1)
Cuando haces búsquedas en perplexity, una de las cosas buenas que tiene, es que te buscan referencias en la web, por lo que imaginemos que usan una «web torticera» entonces tampoco es culpa de un modelo destuneado o tuneado a drede, ya que mezcla resultados, con lo que es un modelo que usa de apoyo. No sé si me explico… es dificil saber de donde saca realmente la info…
Para la IA los modelos abiertos de Deepseek o Meta no son un problema de privacidad, ya que se pueden montar en local sin conexión a Internet
Los modelos que no están en local, por ejemplo todos los de OpenAI, son un agujero de privacidad bastante obvio. Simplemente hay que saberlo y como no somos niños de teta, cada uno a su riesgo, sean chinos, americanos o mongoles
No tengo Google PlayStore en mi teléfono, uso dos tiendas alternativas:
• F-droid
• Aurora Store
Todavía en F-droid DeepSeek no está, pero en Aurora Store estaba desde ayer mismo:
Le acabo de tomar dos capturas de pantalla de mi teléfono a la parte de «Privacidad» de la aplicación y las subí al servicio gratuito de alojamiento de imágenes https://es.imgbb.com/ para compartirlo aquí:
Primera pantalla: https://ibb.co/hykhxpD [
1 Rastreador conocido]Segunda pantalla: https://ibb.co/TKXBRt9
…oh sorpresa…
Este es el tipo de preguntas que hay que hacerle a un sistema razonador…
Demostrar que la subtangente correspondiente a un punto arbitrario de la parábola y^2=4px queda dividida por el vértice en dos partes iguales y que la subnormal es constante e igual a 2p. Construye la gráfica.
Para demostrar que la subtangente correspondiente a un punto arbitrario de la parábola \(y^2 = 4px\) queda dividida por el vértice en dos partes iguales y que la subnormal es constante e igual a \(2p\), seguimos los siguientes pasos:
1. **Ecuación de la tangente y subtangente:**
– Consideramos un punto \((x_1, y_1)\) en la parábola, que satisface \(y_1^2 = 4px_1\).
– La derivada de \(y^2 = 4px\) es \(2y \frac{dy}{dx} = 4p\), por lo que \(\frac{dy}{dx} = \frac{2p}{y}\). La pendiente de la tangente en \((x_1, y_1)\) es \(\frac{2p}{y_1}\).
– La ecuación de la tangente es \(y – y_1 = \frac{2p}{y_1}(x – x_1)\). Al intersectar con el eje x (\(y = 0\)):
\[
-y_1 = \frac{2p}{y_1}(x – x_1) \implies -y_1^2 = 2p(x – x_1) \implies -4px_1 = 2p(x – x_1) \implies x = -x_1
\]
– La subtangente es el segmento desde \((-x_1, 0)\) hasta \((x_1, 0)\), cuya longitud es \(2x_1\). El vértice \((0, 0)\) divide este segmento en dos partes iguales de longitud \(x_1\).
2. **Ecuación de la normal y subnormal:**
– La pendiente de la normal es el recíproco negativo de la pendiente de la tangente: \(-\frac{y_1}{2p}\).
– La ecuación de la normal es \(y – y_1 = -\frac{y_1}{2p}(x – x_1)\). Al intersectar con el eje x (\(y = 0\)):
\[
-y_1 = -\frac{y_1}{2p}(x – x_1) \implies 2p = x – x_1 \implies x = x_1 + 2p
\]
– La subnormal es el segmento desde \((x_1, 0)\) hasta \((x_1 + 2p, 0)\), cuya longitud es \(2p\), constante para cualquier punto en la parábola.
**Conclusión:**
La subtangente en cualquier punto de la parábola \(y^2 = 4px\) es bisecada por el vértice, y la subnormal es constante e igual a \(2p\).
\[
\boxed{2p}
\]
Seguro que los que te vigilan del PCCh son unos tíos muy cultos y ya saben que es la subtangente y la subnormal
Pongo la TV y veo a D. Enrique Dans …… por lo menos han sabido elegir una fuente a la que consultar.
Acaso no esperábamos que se acusase a esta nueva IA de infringir la seguridad????
Cada vez esto se parece más a un mundo feliz.
Se exigirá a las máquinas que tengan más inteligencia que nosotros, algo que será fácil.
«Pero además, lanza (…) a China (…) adecuar (…) legislación (…) privacidad (…) demandas (…) otros países».
Vale, llega tal mensaje a China, y allí mismo les sale un error: «Error de redundancia cíclica», se parten el pecho y siguen adelante como si tal cosa, vamos, como si oyesen llover. Y esto, con todo el cinismo del mundo, lo sabe todo el mundo, valga, nunca mejor dicho la «redundancia».
Off topic but topic.
https://preview.redd.it/puto-tap%C3%B3n-v0-6hbotho6lofe1.jpeg?width=1080&crop=smart&auto=webp&s=984407a2a51cac8b538fc8123e0b1ee3bcf61816
jajaja que bueno…….el p.to tapón con el que no hay quien beba directamente de la botella….
He preguntado a varias IA «es posible que se llegue a instaurar una sociedad como la descrita en el libro «un mundo feliz»
Las respuestas son parecidas, pero me gusta mas la de deepseek.
Resumen: Estamos en el camino correcto.
Te lo supero….
Iiiiiiiassss
Cuando alguien te hablaba desde una cabina, podías tener un cierto margen de seguridad de que la persona «al otro lado» estaba viva y casi garantizado que era la que decía… luego la tecnología siguió avanzando… pero seguimos empeñados en que el comunicante al otro lado del chat es fulanito… o por lo menos el espíritu de fulanito… no hay forma de entender que ningún fulanito analógico necesita estar al otro lado de la linea, que ni siquiera hay cabina analógica y que lo que dice ese fulanitobot, cada vez se parecerá más al lo que decía el otro fulanito analógico???
Debo ser muy muy tontainas… pero yo viví lo de la cabina (el tam tam no) y, por lo tanto mi tontainez es solo una apreciación subjetiva.
Lo único que no ha cambiado es, que solo un fulanito con PODER (para usar cabina telefónica) podía permitirse el lujo de hablar contigo POR TELÉFONO. Como ahora. Y siempre hubo teléfonos (y tambores) de varios colores (o sonoridades)!!!
Las apps chinas hacen con nuestros datos lo mismo que las estadounidenses. Sorpreson. Jamas lo habría imaginado.
«Ya tenemos Golfo de América, por si no nos bastaba con el Subnormal de Sudáfrica.»
—Fuckowski
Perplexity, hazme un resumen del post de Dans
El artículo de Enrique Dans publicado el 28 de enero de 2025 aborda la preocupación sobre la privacidad de los datos personales en aplicaciones chinas populares en Europa.
Los puntos clave son:
Max Schrems y su organización NOYB están investigando apps chinas como TikTok, WeChat, AliExpress, Shein, Temu y Xiaomi por exportar datos personales a China.
La legislación de la UE prohíbe transferencias de datos a países que no garanticen su protección, lo cual es difícil de asegurar en China debido a su sistema de vigilancia 1.
Las empresas chinas podrían enfrentar multas significativas y se les insta a adecuar su legislación de privacidad a las demandas internacionales.
El caso afecta también a Deepseek, una IA china, cuyo uso podría implicar la exportación de datos a China.
Se plantea la posibilidad de que empresas europeas monten servidores propios con modelos como Deepseek para evitar la exportación de datos.
Este escenario plantea desafíos para las relaciones bilaterales entre China y la UE, así como para las empresas tecnológicas chinas que buscan expandirse globalmente.
Traduce el texto de Xaquín a castellano corriente
El texto reflexiona sobre la evolución de la comunicación y cómo ha cambiado nuestra percepción de la autenticidad en las interacciones. Los puntos principales son:
En la era de las cabinas telefónicas, había una mayor certeza de que la persona al otro lado de la línea era quien decía ser y estaba viva.
Con el avance tecnológico, especialmente en la era digital, esta certeza ha disminuido significativamente.
El autor sugiere que seguimos asumiendo erróneamente que hay una persona real detrás de cada interacción en línea, cuando en realidad podría ser un bot o una inteligencia artificial.
Se plantea la idea de que la comunicación digital puede imitar cada vez mejor a la comunicación humana analógica, difuminando la línea entre lo real y lo artificial.
El autor reflexiona sobre su propia experiencia con las cabinas telefónicas y cómo esto influye en su perspectiva actual.