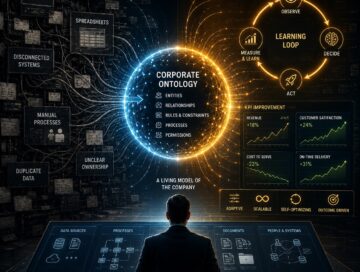
Durante los dos últimos años, las empresas han intentado añadir inteligencia artificial a sus procesos. Al principio sonaba razonable. Workflows existentes, sistemas existentes, datos existentes, cuadros de mando existentes… ahora con inteligencia añadida. Añadir un copilot aquí, un agente allá, unos cuantos pasos automatizados, un modelo conectado a algunas herramientas, y esperar a que aumente la productividad.
Pero este enfoque empieza a mostrar sus límites: el problema no es que la inteligencia artificial no pueda actuar. Cada vez puede hacerlo mejor. El problema es que la mayoría de las empresas no tiene una representación formal de lo que significan sus acciones.
Una empresa no es un montón de aplicaciones. No es un CRM, un ERP, un data lake, un espacio de Slack, ...









![]()
![]()